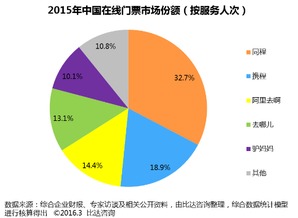
2015年,中國在線門票市場迎來了快速發展期,整體市場規模達到86.5億元人民幣,同比增長顯著,顯示出消費者對互聯網購票方式的高度認可與依賴。這一增長得益于移動互聯網的普及、旅游消費升級以及在線支付技術的成熟。
在競爭格局方面,同程旅游憑借其強大的平臺資源、精準的市場營銷及多元化的產品布局,占據了市場份額第一的位置。其通過與景區深度合作、推出會員特權及節假日促銷等策略,成功吸引了大量用戶,進一步鞏固了市場領先地位。
在線門票市場的興起,不僅為消費者提供了便捷的購票體驗,減少了排隊時間,還推動了旅游行業的數字化轉型。互聯網信息服務在此過程中發揮了關鍵作用,包括大數據分析用戶偏好、智能推薦景區門票,以及通過在線客服和評價系統提升服務質量。
隨著人工智能和5G技術的應用,在線門票市場有望進一步智能化、個性化,為用戶帶來更高效的出行服務。同時,企業需關注數據安全與用戶體驗,以持續推動行業健康發展。總體而言,2015年的市場數據為后續發展奠定了堅實基礎,彰顯了互聯網經濟在旅游領域的巨大潛力。